
 花花鞋
花花鞋
1、需求目标
Android手机上到处可见小红点,以QQ为例,我们可以看到小红点展示如下图所示:
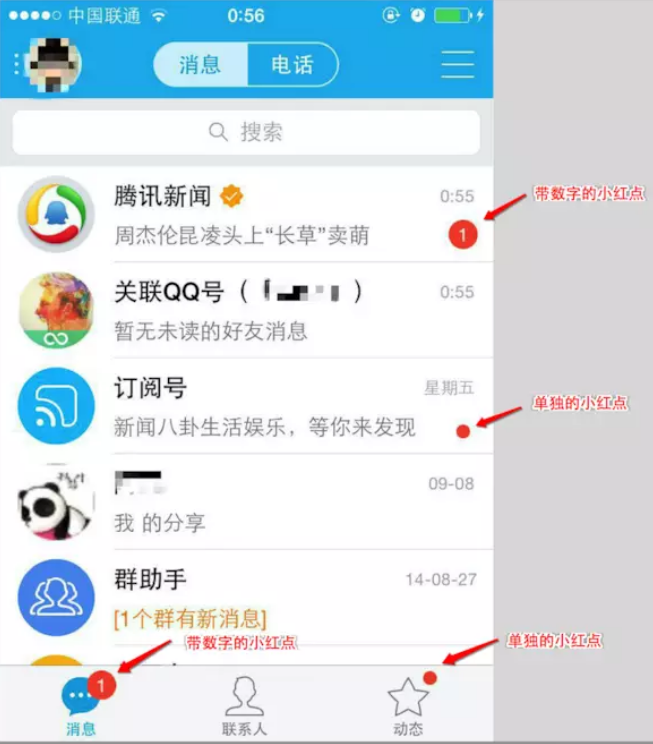
我们就以上面图中小红点为需求目标,来看看我们如何实现这样的小红点功能。
首先我们整理一下需求目标:
- 收到小红点消息并展示在叶子节点和父节点
- 小红点包括单独的小圆点和数字型的小红点
- 除了小红点消息,我们期望我们的代码能支持更多的消息类型
2、研发对需求拆分
接下来我们从研发的角度去拆分这个需求,通过基本的三层架构我们知道单单一个小红点会对应这三层:UI展现层(即小红点如何展示在UI上),业务逻辑层(即小红点交互包含哪些),数据层(小红点消息的来源,以及小红点需要具备哪些属性)。于是我们得到下面的拆分结果:
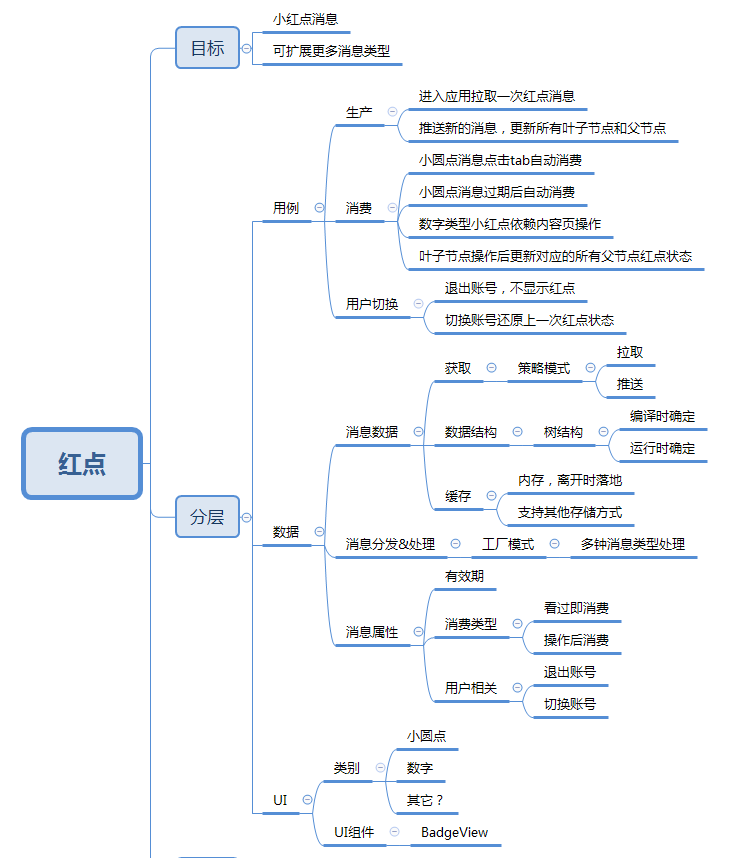
按照上面的3层结构拆分有一个明显的好处是每一层之间都是相互独立的,互不影响。并且有了这些拆分后我们就可以运用架构中一些方法来帮助我们将这些目标实现。
3、架构设计——“4+1”视图
我们先理解一下4+1视图

如上图所示,著名的“4+1”视图包含:逻辑视图,开发视图,过程视图,物理视图
实际的使用过程中这4个视图不会全部用到,例如物理视图描述了最终的工程如何部署,打包,安装的,在我们这次小红点的设计中没有关系。那么我们小红点的设计会包含剩下的3个视图,即:逻辑视图,开发视图,过程视图。我们回顾一下这3个视图的作用:
- 逻辑视图:使用面向对象(OO)的设计方法设计对象模型,我们将小红点按照问题域分解为一些关键的抽象,表现形式为类的形式。并以关联、使用、组合、继承等逻辑关系将它们关联起来
- 过程视图: 过程架构考虑一些非功能性的需求,如性能。它解决
并发、同步、通信等问题,以及逻辑视图的主要抽象如何与过程结构相配合在一起-即在哪个控制线程上,对象的操作被实际执行。例如小红点消息的消息流是怎样流转的,如何设计能避免消息阻塞 - 开发视图:该视图关注软件架构中的模块组织,分层关系。层与层之间的“输入”和“输出”,模块对外部的接口定义。目的是解决团队内多成员协作,模块间解耦和程序可扩展性等目的。例如小红点需求中我们可能不止一个人开发,那么使用开发视图可以很快速的分工,互不影响,同时也为成本评估和计划、项目进度的监控提供依据
3.1、逻辑视图
小红点需求分析中我们大致可以拆分出这些问题域和抽象类:消息如何获取,消息谁来处理,小红点收到消息后需要缓存以便在用户退出后重新登录能获取上次红点状态,小红点UI控件等,详细拆分如下图所示:
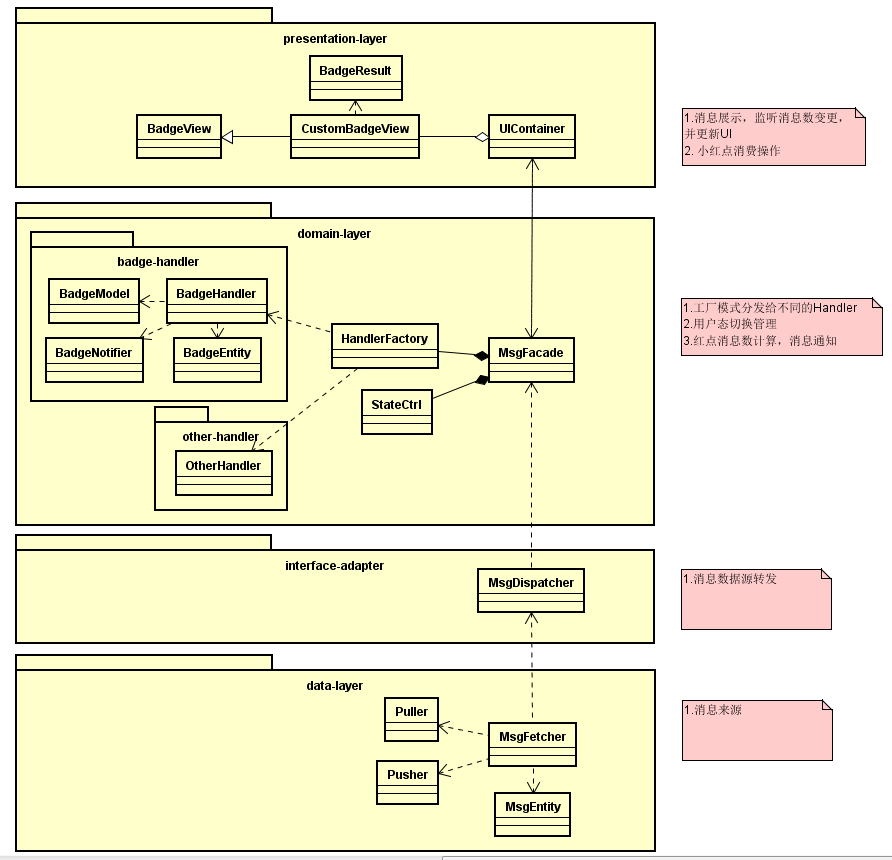
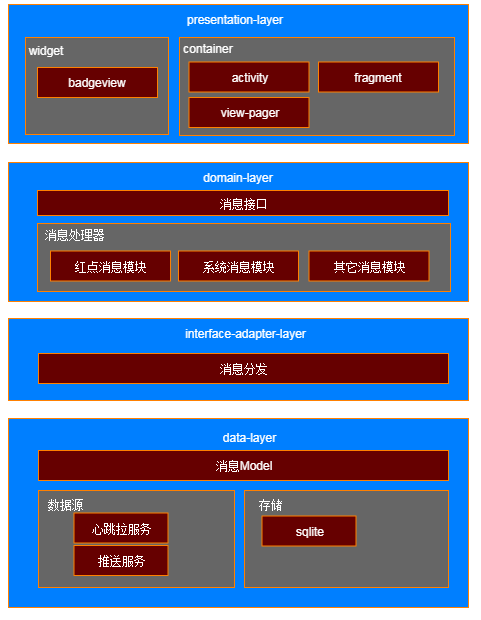
如上图所示,我们将问题域中涉及到的抽象类定义出来,并标出了它们之间的关系。并把它们按照常见的分层方式分在了不同的层级中。
- MsgFetcher: 负责获取数据,获取的方式分拉数据和推数据,简单快速的方式当然是拉取数据(Puller),不过如果消息模块想要及时性高,后续会需要接入推数据(Pusher)。不过这些对于MsgFetcher而言不感知,所以这里可以用设计模式中的策略模式来达到这一目的。
- MsgDispatcher: 负责消息分发,并且放在了interface-adapter层,目的是将数据源和业务实现分离,这样data-layer的改造和数据结构的变动对业务实现不感知。
- MsgFacade: 消息业务的外观类,顾名思义MsgFacade用到了设计模式中的外观模式,对外封装了消息的一些简单的接口,对内则管理消息处理器的构建工厂(HandlerFactory),状态管理(StateCtrl)等具体的工具类。
- HandlerFactory: 消息处理器构建工厂,目的是支持接收除了红点消息外更多的其它消息。毕竟有了牛逼的MsgFetcher,我们怎么只能接收一种消息呢,当然要大作文章。
- BadgeHandler: 红点消息处理器,用于处理具体的红点消息,并自己负责管理红点的缓存。消息不做统一存储是因为从目前的需求来看没这个必要,只要保留它足够的可扩展性就OK了。红点消息使用自己的存储方式可以更轻便快速实现目标。
- UIContainer: 具体的业务容器了,对应到第一幅QQ消息列表视图中的底部Tab选项卡和列表的item项。
- CustomBadgeView: 具体红点UI控件,对应到QQ消息列表截图中的红色小圆点和数字小红点。它继承自BadgeView,但是定制了适合自己App风格的红点style。
- BadgeView: 红点标识的github开源项目,只有一个类,但功能强大,支持小圆点和数字小红点,也可以自己设置红点背景图等。github地址:https://github.com/jgilfelt/android-viewbadger
3.2、开发视图

开发视图需要定义分层,层的“输入”和“输出”,模块,模块的“输入”和“输出”
- msg-fetcher模块:负责消息接收,可以是拉取方式接收,也可以是推送方式接收,这里对应消息源实体MsgEntity
- msg-dispatcher模块:负责消息转发,隔离数据层和业务域层
- msg-handler模块:负责具体消息类型的接收和处理,该模块只接收业务相关的实体BadgeEntity,不依赖data-layer的实体类型,实现解耦
- badgeview模块:负责红点UI展示,该模块只接收BadgeResult类型的数据
3.3、过程视图
对于小红点业务,该设计主要关注红点消息如何流转
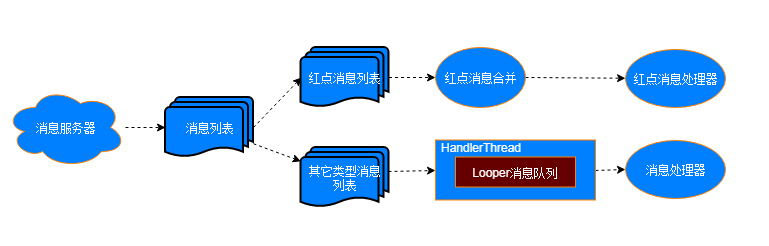
- 消息服务器:消息服务器会批量下发一组消息,该消息列表里面包含各种类型的消息
- 消息分发:该流程步骤会将服务器消息分类,例如包括:红点类型和其它的消息类型。其中红点消息类型也会是一组红点消息列表
- 消息处理:对于普通的消息,需要有一个队列来单独处理,如果消息处理比较耗时,则需要异步处理,可以考虑使用HandlerThread。而对于红点消息比较特殊,一个红点表示一组红点消息的合集结果,最终展示在UI上面的是这个合并结果的数字或小圆点。
4、整体架构设计
有了上面的“4+1”视图分析,我们可以做出我们红点设计的整体架构了
这里我们可以借鉴clean-architecture的思想,下面简单介绍一下clean-architecture:

clean-architecture的主要思想是整体的分层像一个洋葱,外层依赖里面,而里面对外层所使用的技术一无所知。比如里面具体的业务对外层是用拉取的方式获取消息还是用推送的方式获取消息毫无感知
- 最里层的entities: 实体封装的是企业业务规则,对应是应用的业务对象,它们封装着最普通的高级别业务规则
- Use Cases: 在这个层的软件包含应用指定的业务规则,它封装和实现系统的所有用例,这些用例会混合各种来自实体的各种数据流程,并且指导这些实体使用企业规则来完成用例的功能目标。 我们并不期望改变这层会影响实体层. 我们也不期望这层被更外部如数据库 UI或普通框架影响,这层也是因为关注而外部分离的。
- 接口适配器interface-adapters: 这一层的软件基本都是一些适配器,主要用于将用例和实体中的数据转换为外部系统如数据库或Web使用的数据,通常在这个层数据被转换,从用例和实体使用的数据格式转换到持久层框架使用的数据,主要是为了存储到数据库中,这个圈层的代码是一点和数据库没有任何关系,如果数据库是一个SQL数据库, 这个层限制使用SQL语句以及任何和数据库打交道的事情。
- 框架和驱动Frameworks and Drivers: 最外面一圈通常是由一些框架和工具组成,如数据库Database, Web框架等. 通常你不必在这个层不必写太多代码,而是写些胶水性质的代码与内层进行粘结通讯。这个层是细节所在,Web技术是细节,数据库是细节,我们将这些实现细节放在外面以免它们对我们的业务规则造成影响伤害。
借鉴clean-architecture的思想,我们设计出小红点的架构:
由于小红点需求比较简单,暂时涉及不到更多的模块和外部组件,所以每一层里面的模块都很少。如果随着小红点类型增多,处理逻辑变的更为复杂,这里的架构图里面描述的不应该是类,而是模块。
5、其它设计
5.1、小红点存储和查询
小红点逻辑中至关重要的两个点是:
- 红点原始数据存储
- 红点数据查询
a) 红点数据存储
红点数据包含两部分:红点的层级依赖关系,红点的叶子节点原始数据。其中层级依赖关系取决于界面的布局包含关系,这个一般是固定的,或者对外部依赖很强,所以不需要每次程序启动从本地获取。我们只需要存储叶子节点的原始数据即可。
一种简单的存储方式是数据对象存放在内存,这样在程序运行过程中读取和写入非常轻便高效,然后在程序退出时将对象序列化到本地(Gson, fastjson都可以实现),下次程序启动时优先读取本地的红点数据,并异步与服务器远程拉取新的数据合并。
b) 红点数据查询
红点数据查询相对麻烦一些,也是红点消息的关键所在。从文章开始的第一幅图我们可以分析出红点的层级关系和多叉树一致的:父节点的红点展示是它子节点红点消息的合集,这个合成的过程当然需要一些规则。下面的图描述了小红点的层级关系如何反映到多叉树结构中:
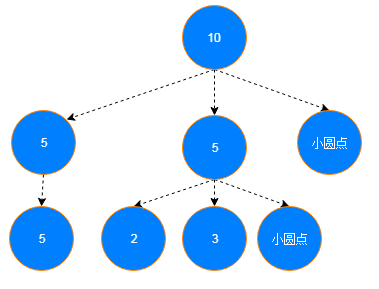
小红点层级展示规则是这样的:
- 如果某一个父节点的子节点中同时包含数字型的小红点和提示型的小圆点,那么数字型的小红点优先级会更高
- 父节点的小红点是它所包含所有叶子节点的状态合集。例如上图中根节点的10,它其实是最下面叶子节点的合集,即:5+2+3+小圆点。然而在有数字小红点存在的情况下,我们可以忽略小圆点,于是得出10这个结果。如果所有的叶子节点中没有数字型小红点,只有一个或多个小圆点,那么父节点就显示小圆点了。
这个多叉树结构只是保存了层级依赖的关系,方便我们快速计算某个父节点包含的所有叶子节点,它并不包含原始数据,所以它与红点原始数据的关系图如下:
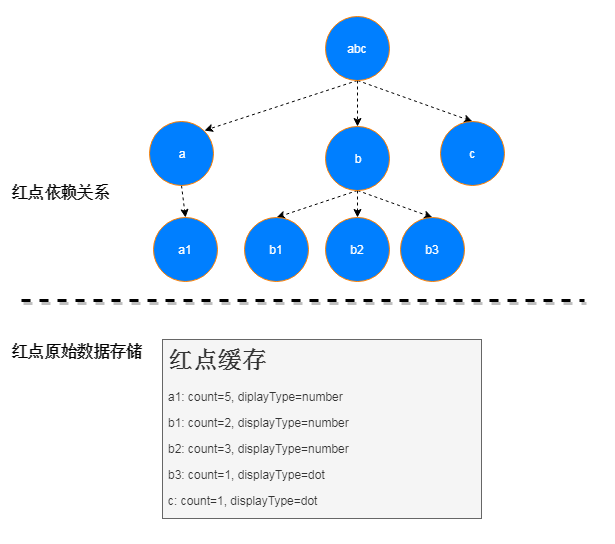
这样的设计另一个作用是将动态的数据源和不变的层级结构隔离开。
5.2、树结构
5.2.1、定义树结构中的节点
|
1 2 3 4 5 6 7 8 9 10 11 |
public static class TreeNode<T> { public T value; public TreeNode<T> parentNode; public List<TreeNode<T>> sonList; public TreeNode(T value, TreeNode<T> parentNode, List<TreeNode<T>> sonList){ this.value = value; this.sonList = sonList; this.parentNode = parentNode; } } |
5.2.2、生成一棵树
例如我要生成这样一颗树:
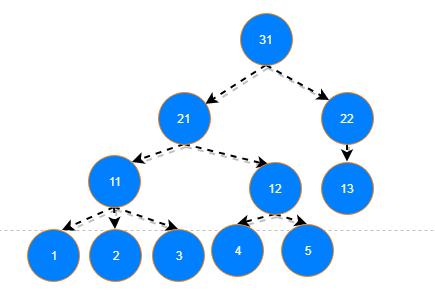
生成代码示例如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
public static void generateTree() { List<MultiTree.TreeNode> sonList11 = new ArrayList<MultiTree.TreeNode>(); List<MultiTree.TreeNode> sonList12 = new ArrayList<MultiTree.TreeNode>(); List<MultiTree.TreeNode> sonList13 = new ArrayList<MultiTree.TreeNode>(); List<MultiTree.TreeNode> sonList21 = new ArrayList<MultiTree.TreeNode>(); List<MultiTree.TreeNode> sonList22 = new ArrayList<MultiTree.TreeNode>(); List<MultiTree.TreeNode> sonList31 = new ArrayList<MultiTree.TreeNode>(); MultiTree.TreeNode node31 = new MultiTree.TreeNode(31, null, sonList31); MultiTree.TreeNode node21 = new MultiTree.TreeNode(21, node31, sonList21); MultiTree.TreeNode node22 = new MultiTree.TreeNode(22, node31, sonList22); MultiTree.TreeNode node11 = new MultiTree.TreeNode(11, node21, sonList11); MultiTree.TreeNode node12 = new MultiTree.TreeNode(12, node21, sonList12); MultiTree.TreeNode node13 = new MultiTree.TreeNode(13, node22, sonList13); sonList21.add(node11); sonList21.add(node12); sonList22.add(node13); sonList31.add(node21); sonList31.add(node22); MultiTree.TreeNode node1 = new MultiTree.TreeNode(1, node11, null); MultiTree.TreeNode node2 = new MultiTree.TreeNode(2, node11, null); MultiTree.TreeNode node3 = new MultiTree.TreeNode(3, node11, null); sonList11.add(node1); sonList11.add(node2); sonList11.add(node3); MultiTree.TreeNode node4 = new MultiTree.TreeNode(4, node12,null); MultiTree.TreeNode node5 = new MultiTree.TreeNode(5, node12,null); sonList12.add(node4); sonList12.add(node5); MultiTree.TreeNode rootNode = node31; List<MultiTree.TreeNode> leafNodeList1 = MultiTree.queryLeafNodeList(rootNode); StringBuilder sb = new StringBuilder(); for(MultiTree.TreeNode node : leafNodeList1) { sb.append(" n:"+node.value); } Log.d("conio", "根节点包含的叶子节点:" + sb.toString()); List<MultiTree.TreeNode> leafNodeList2 = MultiTree.queryLeafNodeList(node12); StringBuilder sb2 = new StringBuilder(); for(MultiTree.TreeNode node : leafNodeList2) { sb2.append(" n:"+node.value); } Log.d("conio", "node12 包含的叶子节点:" + sb2.toString()); List<MultiTree.TreeNode> leafNodeList22 = MultiTree.queryLeafNodeList(node22); StringBuilder sb3 = new StringBuilder(); for(MultiTree.TreeNode node : leafNodeList22) { sb3.append(" n:"+node.value); } Log.d("conio", "node22 包含的叶子节点:" + sb3.toString()); Log.d("conio", "查询值为12的叶子节点:" + MultiTree.queryNode(rootNode, 12).value); List<MultiTree.TreeNode> path = MultiTree.queryParentPath(rootNode, 5); StringBuilder sb4 = new StringBuilder(); for(MultiTree.TreeNode n :path) { sb4.append(" > ").append(n.value); } Log.d("conio", "查询值为5的路径:" + sb4.toString()); } |
输出结果如下:

5.2.3、queryLeafNodeList
使用非递归深度优先遍历查询叶子节点:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
/** * 获取某个父节点下所有的叶子节点 * * @param node * @param <T> * @return */ public static <T> List<TreeNode<T>> queryLeafNodeList(TreeNode<T> node) { List<TreeNode<T>> leafList = new ArrayList<TreeNode<T>>(); Stack<TreeNode<T>> nodeStack = new Stack<TreeNode<T>>(); nodeStack.add(node); while (!nodeStack.isEmpty()) { node = nodeStack.pop(); //获得节点的子节点,对于二叉树就是获得节点的左子结点和右子节点 List<TreeNode<T>> children = node.sonList; int childrenSize = children != null ? children.size() : 0; if (childrenSize > 0) { for(int i=childrenSize - 1; i>=0; i--) { nodeStack.push(children.get(i)); } } else { leafList.add(node); } } return leafList; } |
5.2.4、queryNode
使用非递归深度优先遍历查询:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
public static <T> TreeNode<T> queryNode(TreeNode<T> rootNode, T value) { if(rootNode.value.equals(value)) { return rootNode; } Stack<TreeNode<T>> nodeStack = new Stack<TreeNode<T>>(); nodeStack.add(rootNode); while (!nodeStack.isEmpty()) { TreeNode node = nodeStack.pop(); //获得节点的子节点,对于二叉树就是获得节点的左子结点和右子节点 List<TreeNode<T>> children = node.sonList; int childrenSize = children != null ? children.size() : 0; if (childrenSize > 0) { for(int i=childrenSize - 1; i>=0; i--) { TreeNode<T> child = children.get(i); if(value.equals(child.value)) { return child; } else { nodeStack.push(child); } } } } return null; } |
5.2.5、queryParentPath
向上索引父节点查询整个路径:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
public static <T> List<TreeNode<T>> queryParentPath(TreeNode<T> node) { List<TreeNode<T>> path = new ArrayList<>(); if(node == null) { return path; } TreeNode currentNode = node; while(currentNode != null) { path.add(currentNode); currentNode = currentNode.parentNode; } return path; } public static <T> List<TreeNode<T>> queryParentPath(TreeNode<T> rootNode, T value) { TreeNode<T> node = queryNode(rootNode, value); return queryParentPath(node); } |
6、总结
本文主要在小红点场景中实践了架构设计的一些方法,欢迎大家一起讨论,并指出不对的地方,共同学习共同进步











