
 花花鞋
花花鞋1、前言
链接和装载是一个深度的话题,但其实也没有那么难理解,只是在程序员的历程中很少遇到罢了,但是遇到的时候会比较束手无策,这也是为什么我想写一篇文章展开这个话题的原因。另一个原因是我看到百度上也有很多关于链接和装载的原创文章,给我的感觉是他们都是摘抄《程序员的自我修养》这本书,看似理解又不理解的感觉。毕竟百度就是百度,国内的原创文章少之又少和Google的文章真的是大相径庭。这点我想了一下也不奇怪,的确市面上关于链接与装载的只有两本:国内的一本《程序员的自我修养》和国外的一本《linkers & loaders》, 这两本书我都看过,另外就是Google上面国外大牛的一些文章还是很不错的,还有就是通过工具链自己探索一遍,花了几个月的时间反复阅读和思考,才有了下面的总结文章。这里真的要为我们国内的书《程序员的自我修养》点赞,在全球来说首屈一指,比国外的《linkers & loaders》强太多了。国内的这边书真的是深入浅出,用最浅白的方式带我们逐步领略这个深奥的领域,而国外的那本我再回过头去看的时候发现我理解的知识点在那边真的表达上晦涩难懂,新手去看很容易囫囵吞枣,不知所云。
好了,这是我整理这个知识点的一些感受,废话不多说,下面切入正题。文章中我也会尽量关联到原出处,避免我的结论对大家造成误导。我会以整体俯瞰的角度带大家领略这个知识点,详细的可以回到原出处深入学习和实践。
2、背景知识
2.1、编译型语言和解释型语言
编译、链接、装载都是针对编译型语言,将源代码编译和静态链接成特定格式的二进制文件,该格式便于和动态链接的模块一起在装载阶段映射到进程空间,然后运行。而解释型的语言是将原文件或者半编译的字节码文件交给解释器执行(java是半编译半解释)。
编译型语言是需要针对各个硬件平台去编译的,而解释型的语言由于解释器本身已经针对各个平台编译好了,所以开发者的代码不经过编译,也可以编译成字节码(平台无关语言,例如lua和java的class),将这些中间代码交给虚拟机的解释器去执行。
2.2、计算机&多任务操作系统
2.2.1、虚拟内存
既然编译型语言强依赖计算机硬件,那么必不可少需要对计算机和操作系统有些了解。计算机硬件中有三个部件最为关键:CPU、内存、I/O控制芯片。当一个程序经过编译和链接后装载到内存,我们需要了解一个重要的概念是虚拟内存。
虚拟内存为每个进程提供了一个一致的、私有的地址空间,它让每个进程产生了一种自己在独享主存的错觉(每个进程拥有一片连续完整的内存空间)。这样会更加有效地管理内存并减少出错。虚拟内存的实现需要依赖硬件的支持,对于不同的CPU来说是不同的,但几乎所有的硬件都采用一个叫MMU(Memory Management Unit)的部件来进行页映射,
引用书中的图,程序中使用的虚拟地址经过MMU后转成实际的物理地址。

2.2.2、软件体系结构

在软件体系中,位于最上层的应用程序,比如网络浏览器、多媒体播放器这些客户端程序。从整个层次结构看,开发工具与应用程序都属于同一个层次,因为它们都使用一个相同的接口,就是操作系统应用程序接口API——运行库。例如linux下的libc库,windows32提供的API——win32。
运行库使用操作系统内核层提供的系统调用接口(System call interface),系统调用接口在实现中往往以软件中断的方式提供。而操作系统内核层使用硬件层提供的硬件接口(hardware specification)来编写操作系统和驱动程序,从而与硬件厂商提供的硬件通信。
2.2.3、API和ABI
上面软件体系结构图中我们了解到每个层次之间都需要相互通信,既然通信就必须有一个通信的协议,这个协议就是接口。接口的下面那层是接口的提供者,有它定义接口;接口的上层是接口的使用者,他使用该接口来实现所需要的功能。
我们常知道的接口分两种:API和ABI
API: Application Program Interface
它是一系列从你的程序或者二进制文件中暴露出去给外部使用的类型、变量、函数。在C/C++ 里面就是跟着你的程序一起输出的头文件里面的内容。
ABI: Application Binary Interface
应用程序二进制接口,描述了应用程序和操作系统之间,一个应用和它的库之间,或者应用的组成部分之间的接口。
在很多情况下,链接器为了遵守ABI的约定需要做一些重要的工作。例如,ABI要求每个应用程序包含一个程序中各例程使用的静态数据的所有地址表,链接器通过收集所有链接到程序中的模块的地址信息来创建地址表。ABI经常影响链接器的是对标准过程调用的定义
ABI定义了一些内容 (不限于这些):
- 参数怎么传递给函数(例如:通过栈还是寄存器)
- 函数调用后,由谁来把堆栈恢复原状。—调用结束后,由谁(调用者还是被调用者)负责将参数出栈。
- 函数返回结果存放在哪里
3、编译、链接与装载
3.1、关键概念
在深入展开编译和链接之前,我们先要搞明白以下关键的6个概念:
- 编译
- 目标文件
- 符号
- 链接
- 符号重定位
- 装载
将这些概念串起来正好能描述从源码到运行的整个过程。我们编写的C/C++源代码通过编译器编译成目标文件。编译过程中将解析的符号信息以符号表的方式存放在目标文件中。多个目标文件通过链接器链接成可执行程序。在链接过程中由于目标文件内有对外部符号的引用,这些符号的地址在链接后能确定最终的地址,这个就是符号重定位。最后可执行文件装载到内存运行。
整体流程如下图所示:

3.2、编译
源代码首先经过预处理变成.i文件。预处理的过程包括:对预编译指令的处理,例如:”#include”, “#define”等。编译的过程包括:词法分析、语法分析、语义分析和优化后产生响应的汇编代码文件。编译的过程本文不做详细的展开,它也是一个比较大的话题,我们只要知道编译过程的词法分析阶段,扫描器会将标识符存放在符号表。同时将数字、字符串常量这些存放在文字表。对编译过程感兴趣的可以参考“龙书”深入了解。
3.2.1、目标文件 & linux的ELF文件格式
目标文件是源代码经过编译后但是未进行链接的那些中间文件(例如windows下面的.obj文件、linux下的.o文件)
谈到目标文件我们需要学习它的格式,因为它的格式是专门为将多个目标文件合并,并映射到进程空间的虚拟内存区域而设计的。这个格式在linux下就是ELF格式。既然这种格式的一个作用是为了映射到虚拟内存而设计的,那么除了目标文件,还有其它的文件也是这个格式。包括:可执行文件和动态链接库文件。这里要特别指出的是静态链接库文件(.a文件)不是这种格式,它是把很多目标文件捆绑在一起形成的一个文件,你可以把它理解为一个文件包(或集合)。
顺便提一下还有一种ELF格式的文件——core dump file。我们遇到进程意外终止时,系统可以把该进程的地址空间的内容及终止时的一些其它信息转储到这个核心转储文件。从上面介绍的ELF格式是为了解决映射到虚拟内存而设计的,就不难理解core dump file为啥也是这种格式了。
ELF文件格式
ELF文件格式最明显的是它的 section 机制,它里面包含了很多数量的不同类型的 section。那么我们的源代码是如何对应到ELF格式中的section呢?我们先用一张图来有个更直观的印象。
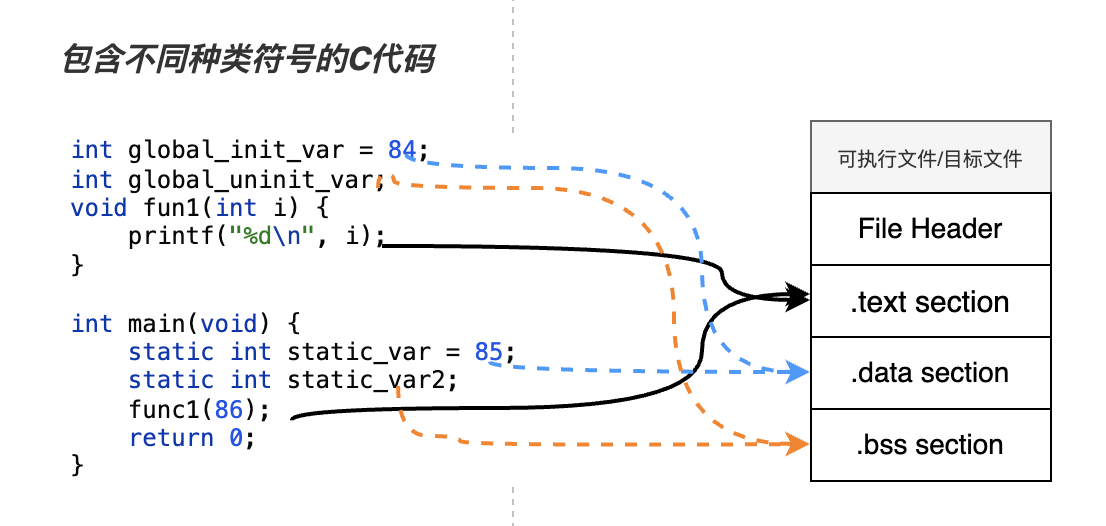 通过这个图我们可以简单的了解到ELF文件格式的特征:以各种各样的section将源代码分割。这种形式主要是方便链接阶段多个目标文件合并,也方便运行阶段如何操作该文件映射后的内存
通过这个图我们可以简单的了解到ELF文件格式的特征:以各种各样的section将源代码分割。这种形式主要是方便链接阶段多个目标文件合并,也方便运行阶段如何操作该文件映射后的内存
每个section都有特定的含义,例如:.text是代码段、.data是数据段、.bss一般用来存放未初始化的全局变量或者局部静态变量。除此之外还有很多其它的section,例如下面会提到的.symtab(符号表),.dynsym(动态符号表) 等。
3.3、符号
了解了目标文件,我们就可以开始学习符号这个重要的概念了~
链接的过程其实就是将多个不同的目标文件之间相互“粘”在一起。符号包括变量和函数。每一个目标文件都有对其它目标文件中定义的符号的引用和在自己内部的符号定义。所以在链接中,目标文件之间相互拼接实际上是目标文件之间对符号地址的引用。
每一个目标文件都会有一个相应的符号表(Symbol Table),这个表里面记录了目标文件中所用到的所有符号。理解符号和符号表对于下面篇幅中介绍的链接过程非常有帮助。
3.3.1、符号的历史
符号最早是汇编语言引入的,在汇编语言之前有一段时间程序员使用机器语言编码。相比机器语言,汇编语言使用接近人类的各种符号和标记来帮助记忆。如上面提到的,符号在目标文件中的存在形式是在符号表中映射到具体的地址。这样符号表极大的方便了在链接的过程中将该符号出现的地方替换(重定位)成对应的虚拟内存地址。
3.3.2、符号分类
如上面所说,链接中最主要面向全局符号(静态符号不参与链接),包含2种:定义在本目标文件中的全局符号 和 在本目标文件中引用的全局符号
- 定义在本目标文件中的全局符号:该符号可以被其它目标文件引用。
- 在本目标文件中引用的全局符号:该符号没有定义在本目标文件,又叫“外部符号”
其它符号:
- 局部符号:例如static修饰的符号
- 其它符号:段名、行号信息等
3.3.3、符号表
目标文件中的符号表分为3种:符号表、全局符号表和动态共享库中的动态符号表。
分析ELF格式文件的工具
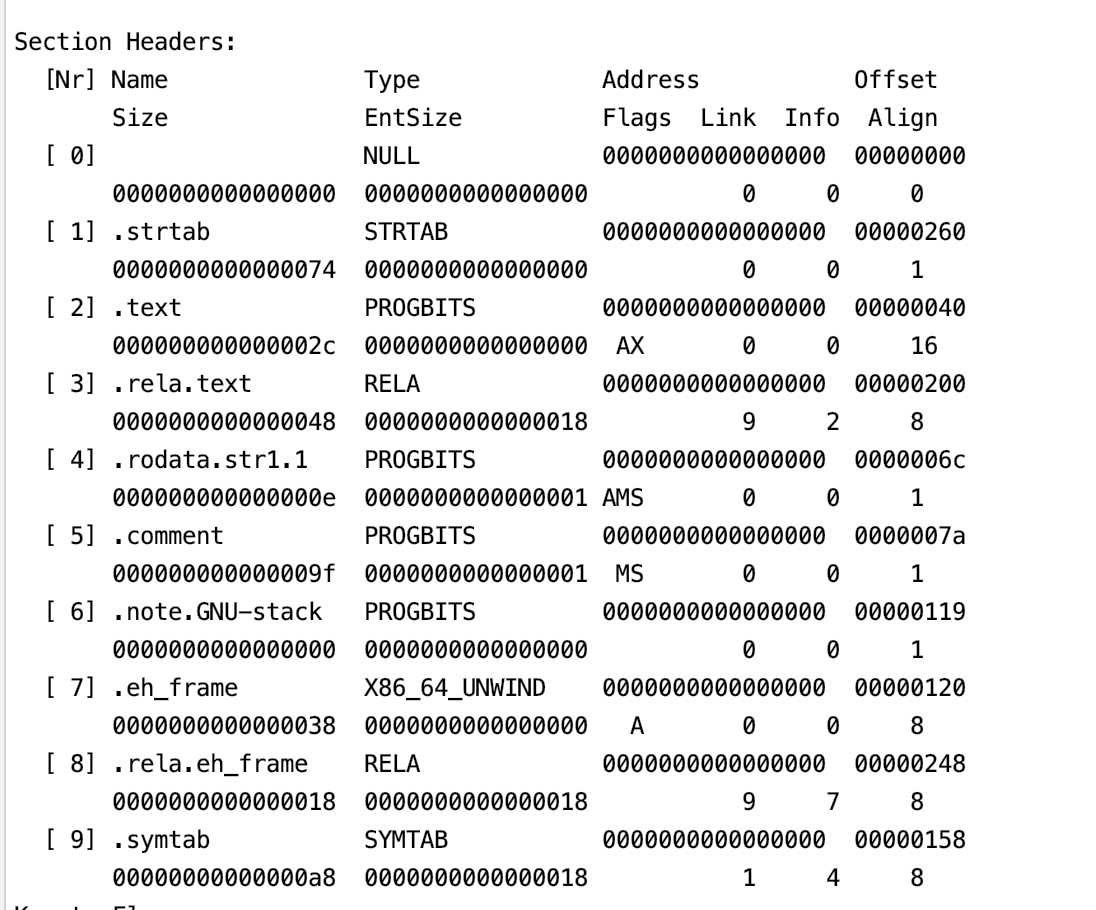
工欲善其事必先利其器,这些二进制文件里面包含什么样的内容呢?我们需要借助一些工具来分析里面的内容,主要有两个工具readelf 和 objdump。它们展示的内容有些差异,可以结合着一起看。例如我们想看目标文件里面有哪些 section.
- readelf
|
1 |
readelf -S lib.o |
结果如下:
- objdump
|
1 |
objdump --section-headers lib.o |
结果如下:

符号表的内容:
符号表在ELF格式文件中的段名一般为”.symtab“。符号表里面保存了所有的符号。包括目标文件内部的符号(私有变量和函数),也包括导入导出的符号。
接下来我们写一个简单的C程序,来边实践边继续我们的话题:
- 首先准备环境:
我当前是一台mac电脑,不属于linux环境。但是我们可以用跨平台编译工具解决这个问题,首先我想到的是android的NDK。
详细如何使用NDK来构建不同CPU架构的下的目标文件,可以参考这篇文章:链接
下载了NDK后,我们将我们的环境变量配上工具链的路径,方便我们使用里面的工具。

2. 编写简单的源代码程序
lib.c
|
1 2 3 4 5 6 7 |
#include <stdio.h> #include <unistd.h> void foobar(int i) { printf("foobar in lib"); sleep(-1); } |
该代码中定义了foobar函数。
记住在linux环境下如果没有加static修饰,默认定义的符号都会导出,而对于windows默认符号都不会导出(可添加
__declspec( dllexport )在符号前面修饰,标识该符号为导出符号)
3.构建目标文件
|
1 |
x86_64-linux-android28-clang -c lib.c |
于是我们在我们的当前目录下得到一个lib.o 目标文件
从lib.c的源码我们可以了解到,该文件里面没有静态符号。只有导入导出符号,总共应该有3个 —— 导出符号为:foobar(在当前目标文件中有定义,且默认导出);导入符号:printf 和 sleep(这些是libc运行时库的导出符号)。
源代码的内容都会映射到ELF格式文件的section中,而符号都会存放在符号表(.symtab)中。我们可以用下面的命令查看符号表:
|
1 |
readelf -s lib.o |
输出结果如下:
|
1 2 3 4 5 6 7 8 9 10 11 |
ali@B-VL4BMD6M-2245 cpp % readelf -s lib.o Symbol table '.symtab' contains 7 entries: Num: Value Size Type Bind Vis Ndx Name 0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND 1: 0000000000000000 0 FILE LOCAL DEFAULT ABS lib.c 2: 0000000000000000 14 OBJECT LOCAL DEFAULT 4 .L.str 3: 0000000000000000 0 SECTION LOCAL DEFAULT 2 .text 4: 0000000000000000 44 FUNC GLOBAL DEFAULT 2 foobar 5: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND printf 6: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND sleep |
我们看到有3个全局符号,其它的local符号主要是section名字和文件名。3个全局符号中有两个Ndx为UND(printf和sleep),UND代表未在本目标文件中定义,它是定义在其它文件中。另一个全局符号是有值的(foobar),它是定义在当前模块的全局符号。这个结果我们上面的源代码对应的上了。
动态符号表在目标文件中的section是”.dynsym“。动态符号表只保存了模块中符号导出、导入信息。这个是专门为了动态链接使用的表,用于表示动态链接这些模块之间的符号导入导出关系。符号表(.symtab)里面包含了动态符号表里面的所有符号。
至于说全局符号表,链接器中有一张全局符号表,所有输入文件中定义或者引用的每一个符号,都会在表中对应一个表项。每次链接器读入一个输入文件,它会将该文件中所有的全局符号加入到这张符号表中。
在动态链接中动态链接器完成自举后,动态链接器将可执行文件和链接器本身的符号表都合并到一个符号表中(全局符号表)。然后链接器开始寻找可执行文件所依赖的共享对象(.dynamic 段中的DT_NEEDED类型的项标记了它依赖的共享对象),然后继续遍历每个共享对象,同样读取它们的.dynamic (动态连接表,下面会介绍)section,遍历的方式找到它依赖的共享对象,直到所有依赖的共享对象都被装载进来为止。
当一个新的共享对象被装载进来的时候,它的符号表会被合并到全局符号表中,所以当所有的共享对象都被装载进来的时候,全局符号表里面将包含进程中所有的动态链接所需要的符号。
相关参考文档:global-symbol-table
3.3.4、符号冲突
符号冲突也是一个较复杂的话题。在C语言的时代,它是没有命名空间的,这样不言而喻会在使用中经常遇到符号冲突的问题。后面C++引入后,有了namespace、class后基本解决了符号冲突问题,但也增加了编译器和链接器的复杂度。
既然C没有C++强大,那我们为啥还要解决C的符号冲突问题?我们先了解一下什么是ANSI C。
ANSI C
虽然C++非常强大,但是现实应用中我们仍然离不开C,他是当前硬件支持范围最广的一套标准,在目前主流的硬件平台可移植性最好。如主流的C库包括:lua、curl等都是基于ANSI C。
以下是摘自维基百科对ANSI C的描述:
ANSI C、ISO C、Standard C是指美国国家标准协会(ANSI)和国际标准化组织(ISO)对C语言发布的标准。历史上,这个名字专门用于指代此标准的原始版本,也是支持最好的版本(称为C89或C90)。使用C的软件开发者被鼓励遵循标准的要求,因为它鼓励使用跨平台的代码。
强符号&弱符号
对于C/C++语言来说,编译器默认函数和初始化了的全局变量为强符号,未初始化的全局变量为弱符号。也可以通过GCC的“attribute((weak))”来定义任何一个强符号为弱符号。
需要注意的是:强符号和弱符号都是针对定义来说的,不是针对符号的引用。例如如果源代码有有这样一句 extern int ext; 那么 ext 既非强符号也非弱符号,因为它是一个外部变量的引用。
与之对应的还有“弱引用”和“强引用”,代码中对外部符号的引用默认为”强引用“,即默认对外部目标文件的符号引用在目标文件最终链接成可执行文件时,它们需要被正确的找到符号的定义,如果没有找到,那么链接器就会报符号未定义错误。我们也可以明确的指定一个符号的引用为“弱引用”, 例如GCC中,可以通过 “attribute((weakref))” 这个关键字来声明对一个外部函数的引用为弱引用。示例如下:
|
1 2 3 4 5 |
__attribute((weakref)) void foo(); int main() { foo(); } |
这样如果这个符号在全部目标文件中都未定义,我们将它编译成一个可执行文件的时候,并不会报链接错误,但是运行时会异常,因为foo的函数地址为0,会发生非法地址访问的错误。
弱符号和强符号是语言特意保留的一种特性,在允许符号重复的同时,提供了一种非常有用的能力,比如库中定义的弱符号可以被用户定义的强符号覆盖,从而使得程序可以使用自定义版本的库函数,或者程序可以对某些拓展功能模块的引用定义为弱引用,当我们将扩展模块和程序链接在一起的时候,功能模块就可以正常使用;此时如果我们去掉某些功能模块,那么程序也可以正常链接,只是缺少了相应的功能,这使得程序的功能更加容易裁剪和组合。
链接器如何处理符号冲突
由于弱符号和强符号的存在,以及动态库(动态共享库在运行时决定符号地址)和静态库的引入,我们需要理解链接器如何处理这些重复符号的。只有理解这些机制才能避免意料之外的符号覆盖和重复定义错误,以及期望的符号新版本覆写旧版本能正常运行。
总结三个点:
- 多个.o目标文件参与静态链接:所有.o文件中不允许强符号被多次定义。多个强符号出现会报错;一个强符号多个弱符号,取强符号;都是弱符号,选择占用空间最大的一个弱符号。
- .a 静态库文件与.o文件,.a与.so动态共享库文件:(.a文件参与静态链接,前面介绍过他不是一个ELF格式文件,它更像是一个多个.o目标文件的集合包)。静态链接库参与链接时与.o目标文件,以及与.so动态共享库文件的优先级平级,此时符号的优先级取决于链接时文件的先后顺序
- .o目标文件与.so动态共享库文件:此时.o目标文件优先级高,对于链接时它们两种文件的顺序无关。这里涉及到“全局符号介入”的问题,所以.so动态共享库文件的优先级始终比.o目标文件低。
用一张图表示这三种类型文件之间的关系:

全局符号介入:动态链接允许符号重复, 冲突解决规则是当一个符号需要被加入全局符号表时,如果相同的符号已经存在,则后加入的符号被忽略
实践示例:
多个.o文件的例子比较简单,这里就跳过。我们直接从2和3开始验证:
我们定义3个C程序:
program1.c
包含一个外部 a 符号的强应用:
|
1 2 3 4 5 6 7 8 9 |
#include "lib.h" extern int a; int main() { foobar(a); return 0; } |
lib.h
申明了一个强符号引用 —— foobar
|
1 2 3 4 5 |
#ifndef TESTEMPTY_LIB_H #define TESTEMPTY_LIB_H void foobar(int i); #endif |
lib.c
定义了一个强符号 —— a,它的值为123,和另一个强符号函数foobar
|
1 2 3 4 5 6 7 8 |
#include <stdio.h> #include <unistd.h> int a = 123; void foobar(int i) { printf("foobar in lib:%d\n", i); sleep(-1); } |
lib2.c
定义了一个弱符号 —— a,它的值为345
|
1 2 3 4 5 6 7 8 |
#include <stdio.h> #include <unistd.h> __attribute__((weak)) int a = 345; __attribute__((weak)) void foobar(int i) { printf("foobar in lib2:%d\n", i); sleep(-1); } |
编译:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
//lib.a x86_64-linux-android28-clang -c lib.c x86_64-linux-android-ar -r lib.a lib.o //lib2.o x86_64-linux-android28-clang -c lib2.c //program1.o x86_64-linux-android28-clang -c program1.c //链接成a.out,并跟踪 a 符号 x86_64-linux-android28-clang program1.o lib2.o lib.a -Wl,-trace,-trace-symbol=a |
- 链接顺序:x86_64-linux-android28-clang program1.o lib2.o lib.a
我们根据上面的知识点,判断满足第2点。此时.a 和 .o文件里面的符号的优先级是一样的,此时取决于顺序。lib2.o 在链接顺序上排在 lib.a 的前面,所以使用的lib2.o里面的弱符号 345(尽管lib.a静态库里面有个强符号的值为123)。
我们实际运行一下a.out看下结果:
|
1 2 |
130|root@x86_64:/sdcard/test # ./a.out foobar in lib2:345 |
- 交换一下 lib.a 和 lib2.o 的链接顺序:x86_64-linux-android28-clang program1.o lib.a lib2.o
此时是lib.a里面的符号值 —— 123
|
1 2 |
130|root@x86_64:/sdcard/test # ./a.out foobar in lib:123 |
- .a 与 .so 动态共享库文件: x86_64-linux-android28-clang program1.o lib.a lib2.so
首先我们先构建一个.so 动态共享库文件 lib2.so
|
1 |
x86_64-linux-android28-clang -shared -o lib2.so lib2.c |
得到lib2.so后,我们顺序链接 program1.o,lib.a, lib2.so。从上面的知识点我们可以判断,此时应该会用lib.a里面的强符号a的值 —— 123。
执行a.out之前,我们需要提前将lib2.so 放在动态链接的搜索路径上,例如我是在Android模拟器的linux环境下的sdcard/test目录下面放置lib2.so,所以配置如下:
|
1 |
export LD_LIBRARY_PATH=/sdcard/test/:$LD_LIBRARY_PATH |
我们验证一下这次链接输出文件a.out,结果如下(验证了我们的判断):
|
1 2 |
root@x86_64:/sdcard/test # ./a.out foobar in lib:123 |
同样我们交换一下链接顺序,如下:
- x86_64-linux-android28-clang program1.o lib2.so lib.a
此时通过上面第2点的结论,我们可以判断此时应该走的lib2.so 里面弱符号 a 的值 —— 345,我们同样验证一下结果:
|
1 2 |
130|root@x86_64:/sdcard/test # ./a.out foobar in lib2:345 |
打印的是345,也验证了我们的结论~
- .o 文件与动态共享库链接,始终以.o文件的符号优先级最高:x86_64-linux-android28-clang program1.o lib2.o lib.so
此时lib2.o里面的是弱符号(值为345),lib.so里面的是强符号(值为123),所以无论2个文件的链接顺序是什么样的,打印的值始终为345。我们确认一下结果:
|
1 2 |
130|root@x86_64:/sdcard/test # ./a.out foobar in lib2:345 |
交换一下链接顺序:x86_64-linux-android28-clang program1.o lib.so lib2.o,最后输出也是同上。所以也验证了我们的结论~
运行时链接的符号
谈到符号优先级,上面的知识已经是链接时最难的部分了,理解了上面的知识就能解决日常开发中的绝大部分问题。但是从完整性的角度来看,我们还需要了解另一种运行时链接的符号。运行时链接的使用场景是我们在运行过程中通过一个函数来打开一个动态共享库(例如:dlopen),这个函数将动态共享库加载到进程空间,并完成初始化过程。dlopen 的返回值是被加载的模块的句柄,我们可以通过这个句柄进行符号查找。此时该句柄查找的符号只是从dlopen打开的共享对象为根节点,对它所有依赖的共享对象进行广度优先遍历,直到找到符号为止。而不会从全局符号表中找符号了,也就是说即使和全局符号表中的符号冲突了,也没有关系,仍然走该dlopen的共享对象的依赖序列符号查找方式。
此外dlopen有个参数(RTLD_GLOBAL)可以设置将被加载的模块的全局符号合并到进程的全局符号表中,使得以后加载的模块可以使用这些符号。
3.4、链接
链接从时机上面分为静态链接和动态链接。对于静态链接来说,它是由静态链接器在编译后的链接阶段完成的,整个链接过程就是将几个输入的目标文件加工后合并成一个输出文件。有人会有疑问:那么.a静态库文件呢,它不是目标文件,它是怎么参与编译的呢?上面我们介绍到.a静态库文件是多个.o目标文件的集合,实际参与链接的还是里面的.o目标文件。
既然静态链接的过程是将多个输入的目标文件合并成一个输出文件,那么链接器是如何将它们链接起来的呢?这个过程发生了什么呢?还有动态链接又是啥,为啥有了静态链接后还需要有动态链接呢?带着这些问题我们来一步一步揭开链接的神秘面纱~
3.4.1、静态链接
上面提到静态链接的过程是将多个目标文件合并,而怎么合并涉及到目标文件的格式。从上面的目标文件的格式我们了解到在linux下它是ELF格式,ELF格式将文件按照不同的类型拆分成多个section,而静态链接器实际就是将多个目标文件的相同性质的section合并到一起。比如将所有的输入文件的“.text”合并到输出文件的“.text”段。那么我们现在明白了目标文件格式的分section的思想是为了解决多个目标文件最终合并成一个文件,并方便映射到进程虚拟内存空间的问题而设计的了。(任何一个设计的背后有它需要解决的问题,所谓不是为了设计而设计就是这个意思)
简单合并后不是直接可以运行了,因为合并后空间变了,符号的偏移变了(即符号地址也随着改变了),静态链接器还需要加工一下这个合并后的文件才能保证它可执行。
静态链接器采用一种“两步链接”(Two-pass Linking)的方法,即整个链接过程分两步:(摘抄自来自《程序员的自我修养》第101页)
第一步:空间与地址分配:扫描所有的输入目标文件,获得它们的各个段的长度、属性和位置,并且将输入目标文件中的符号表中所有的符号定义和符号引用收集起来,统一放到一个全局符号表中。这一步中,链接器将能够获得所有输入目标文件的段的长度,并且将它们合并,计算出输出文件中各个段合并后的长度与位置,并建立映射关系。
第二步:符号解析和重定位:使用上面第一步中收集的所有信息,读取输入文件中段的数据、重定位信息,并且进行符号解析与重定位、调整代码中的地址等。事实上第二步是链接过程的核心,特别是重定位过程。
我们用一张大图整体理解一下源码参与静态链接后映射到内存的状态流转:
 1. 生成目标文件:C 源代码通过编译器(clang等)编译成目标文件格式(Linux下的ELF格式)。
1. 生成目标文件:C 源代码通过编译器(clang等)编译成目标文件格式(Linux下的ELF格式)。
- 多个目标文件合并:多个目标文件通过静态链接器(ld)将相同类型的section合并(例如: .text、.data)。同时会进一步优化,将多个section合并为一个segment(段)。目的是对于相同权限的section,把它们合并到一起当作一个segment来映射,segment按内存页大小对齐,方便接下来加载器的内存管理。
-
全局符号表:同时收集全局符号引用和定义到“全局符号表”中,并在链接的过程中更新该全局符号表中的符号地址(图中黄色区域中ld到全局符号表的箭头)
-
符号地址重定位:接下来是重定位,重定位依赖目标文件中的重定位表(包含:重定位入口位置、重定位入口的类型和符号在符号表的下标),目的是确定符号在section中的位置、并修改该位置符号的目标地址。(下面会详细介绍静态链接器如何使用这些信息重定位符号的目标地址的)
-
加载到内存:加载器将可执行文件中的segment映射到虚拟内存,虚拟内存到物理内存的映射是通过“页错误”触发的 —— 在执行发现空页面是发出一个“页错误”,交给操作系统分配一块物理内存MMU到对应的虚拟页,并继续交给进程执行
接下来我们借助工具详细了解一下整个静态链接和装载的过程发生了什么~
3.4.1.1、生成目标文件
示例图中我们准备了两个C程序:a.c, b.c。b.c 里面定义了两个全局符号,变量shared和函数swap。a.c里面引用了这两个符号。这两个源代码通过编译工具生成目标文件后,在linux下是有多个section组成的ELF格式文件,我们可以通过 readelf 和 objdump 来查看这种格式文件中的内容,例如我们想看文件中有哪些section:
- 查看目标文件包含哪些section: readelf -S xxx.o 或 objdump -h xxxx.o
输出如下:
a.o
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
B-VL4BMD6M-2245 jni % readelf -S a.o There are 10 section headers, starting at offset 0x288: Section Headers: [Nr] Name Type Address Offset Size EntSize Flags Link Info Align [ 0] NULL 0000000000000000 00000000 0000000000000000 0000000000000000 0 0 0 [ 1] .strtab STRTAB 0000000000000000 00000212 0000000000000076 0000000000000000 0 0 1 [ 2] .text PROGBITS 0000000000000000 00000040 0000000000000034 0000000000000000 AX 0 0 4 [ 3] .rela.text RELA 0000000000000000 000001b0 0000000000000048 0000000000000018 9 2 8 [ 4] .comment PROGBITS 0000000000000000 00000074 0000000000000030 0000000000000001 MS 0 0 1 [ 5] .note.GNU-stack PROGBITS 0000000000000000 000000a4 0000000000000000 0000000000000000 0 0 1 [ 6] .eh_frame PROGBITS 0000000000000000 000000a8 0000000000000030 0000000000000000 A 0 0 8 [ 7] .rela.eh_frame RELA 0000000000000000 000001f8 0000000000000018 0000000000000018 9 6 8 [ 8] .llvm_addrsig LOOS+0xfff4c03 0000000000000000 00000210 0000000000000002 0000000000000000 E 9 0 1 [ 9] .symtab SYMTAB 0000000000000000 000000d8 00000000000000d8 0000000000000018 1 6 8 |
b.o
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
B-VL4BMD6M-2245 jni % readelf -S b.o There are 10 section headers, starting at offset 0x228: Section Headers: [Nr] Name Type Address Offset Size EntSize Flags Link Info Align [ 0] NULL 0000000000000000 00000000 0000000000000000 0000000000000000 0 0 0 [ 1] .strtab STRTAB 0000000000000000 000001b0 0000000000000077 0000000000000000 0 0 1 [ 2] .text PROGBITS 0000000000000000 00000040 0000000000000024 0000000000000000 AX 0 0 4 [ 3] .data PROGBITS 0000000000000000 00000064 0000000000000004 0000000000000000 WA 0 0 4 [ 4] .comment PROGBITS 0000000000000000 00000068 0000000000000030 0000000000000001 MS 0 0 1 [ 5] .note.GNU-stack PROGBITS 0000000000000000 00000098 0000000000000000 0000000000000000 0 0 1 [ 6] .eh_frame PROGBITS 0000000000000000 00000098 0000000000000028 0000000000000000 A 0 0 8 [ 7] .rela.eh_frame RELA 0000000000000000 00000198 0000000000000018 0000000000000018 9 6 8 [ 8] .llvm_addrsig LOOS+0xfff4c03 0000000000000000 000001b0 0000000000000000 0000000000000000 E 9 0 1 [ 9] .symtab SYMTAB 0000000000000000 000000c0 00000000000000d8 0000000000000018 1 7 8 |
分析两个目标文件,我们可以暂时只关心这几个section: .text, .data, .symtab。他们分别放置代码、数据、和符号表。
对比b.o和a.o我们看到b.o 多出了 .data section,是因为它定义了数据,而 a.o 没有,因为它没有定义数据,而是引用了外部的数据。
我们看下b.o 的这两个定义的符号分别位于哪些section,我们可以查看符号表来获取这些信息~
- 查看目标文件符号表:readelf -s xxxx.o 或 objdump –syms xxxx.o
输出如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
B-VL4BMD6M-2245 jni % readelf -s b.o Symbol table '.symtab' contains 9 entries: Num: Value Size Type Bind Vis Ndx Name 0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND 1: 0000000000000000 0 FILE LOCAL DEFAULT ABS b.c 2: 0000000000000000 0 NOTYPE LOCAL DEFAULT 3 $d.1 3: 0000000000000000 0 NOTYPE LOCAL DEFAULT 4 $d.2 4: 0000000000000000 0 NOTYPE LOCAL DEFAULT 6 $d.3 5: 0000000000000000 0 NOTYPE LOCAL DEFAULT 2 $x.0 6: 0000000000000000 0 SECTION LOCAL DEFAULT 2 .text 7: 0000000000000000 4 OBJECT GLOBAL DEFAULT 3 shared 8: 0000000000000000 36 FUNC GLOBAL DEFAULT 2 swap |
我们可以看到两个符号: shared 和 swap ,它们的TYPE 分别为 OBJECT 和 FUC。然后Ndx 为 3 和 2。如果是该目标文件定义的符号,那么Ndx就是该符号在 section 表中的下标。通过上面第一个的命令我们可以看到 3 和 2 分别对应 .data 和 .text 两个section。所以可以知道 shared 位于 .data ,而swap符号位于 .text section。当Ndx表示 section表中的下标时,此时的Value表示在 section中的偏移,此时都是0,Size表示该符号占的空间。
更多关于符号表和section header可以参考《程序员的自我修养》的82页-ELF符号表结构。
3.4.1.2、多个目标文件合并
1、链接成可执行文件
使用android工具链中的ld工具,命令行如下:
|
1 |
arm-linux-androideabi-ld a.o b.o -e main -o ab |
得到一个输出为 “ab” 的文件
2、可执行文件结构
当目标文件合并成可执行文件后,引入了一个新的概念——段(segment)。我们这么理解,section是存在于“可重定位文件”的,它包含代码节和数据节(以section形式存在)。此文件适合与其他可重定位目标文件链接,从而创建动态可执行文件、共享目标文件或其他可重定位目标文件。所以section是For链接器使用的,而segment是For加载器的。加载器不关心每个section的细节,它只关心2个点:
- 如何映射到内存页(因为计算机是按页管理内存的)
- 如何操作这些内存页里面的内容
对于第一点,段(segment)按页大小对齐,一个段包含多个section。一个段在进程虚拟空间中对应一个VMA(虚拟内存区域)。跨段(segment)的虚拟页(VMA)会共享一个物理页(一种内存管理方式,对于应用而言,它们只知道虚拟内存,所以2个段内存是相互独立的,但是实际物理内存可能会共用)。
对于第2点,segment会对于相同权限的section,把它们合并到一起当作一个segment来映射,例如只读的放在一个segment,可读可写的section都放在另外一个segment。
更多关于“目标文件格式”的介绍可以参考这篇文章:链接
通过 readelf -l <可执行文件> 可以查看section和segment的关系。示例如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
B-VL4BMD6M-2245 jni % readelf -l ab Elf file type is EXEC (Executable file) Entry point 0x4000e8 There are 3 program headers, starting at offset 64 Program Headers: Type Offset VirtAddr PhysAddr FileSiz MemSiz Flags Align LOAD 0x0000000000000000 0x0000000000400000 0x0000000000400000 0x0000000000000190 0x0000000000000190 R E 0x10000 LOAD 0x0000000000000190 0x0000000000410190 0x0000000000410190 0x0000000000000004 0x0000000000000004 RW 0x10000 GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 RW 0x10 Section to Segment mapping: Segment Sections... 00 .text .eh_frame 01 .data 02 |
我们看到可执行文件”ab“有3个segment。我们只关心 “LOAD” 类型的2个segment,第一个segment包含 .text 和 .eh_frame,这个segment的flag为 R E,它代表该段的属性为只读和可执行。另一个segment包含 .data,这个segment的flag为RW,它代表该段的属性为可读可写。这个很好的解释了上面提到的第2点。
我们再看下2个LOAD 类型segment的对齐属性都是0x10000,也就是64K的内存空间,同时两个LOAD的段的虚拟地址(VirtAddr)之间相差是0x10000的整数倍(不考虑offset)。
segment特有的两个关键属性Flags和Align,有效的帮助加载器去将可执行文件映射(Align)到内存,并告诉系统如何操作(Flags)这些映射进来的段。
3.4.1.3、全局符号表
全局符号表不是存在于目标文件的结构,而是在过程中存在的,例如静态链接过程。全局符号表的概念可以回到上面“全局符号表”再回顾一下它的介绍。全局符号表在最终重定位符号地址的操作中起到至关重要的作用,首先它在链接的第一步(见上面的两步链接)时将输入目标文件中的符号表中所有的符号定义和引用收集起来,统一放到一个全局符号表,此时静态链接阶段我们就得到了一个“全局符号表”。
接下来链接器需要更新“全局符号表”的地址,我们知道在链接第一步时会扫描和分配空间,这时输入文件中的各个section在链接后的虚拟地址就已经确定了,比如“.text” 为 0x004000e8。又因为各个符号在section内的相对位置也是固定的,所以这些全局符号(shared, swap)的地址也已经是确定的了,链接器只需要给每个符号加上一个偏移量,使他们能够调整到正确的虚拟地址。这样各个符号的最终地址就更新到“全局符号表”中了。
有了这张至关重要的全局符号表,下面介绍的重定位就能简单的完成符号的重定位工作了。
3.4.1.4、符号地址重定位
- 重定位是啥?
我们以上面的示例a.c举例,a.c中引用了全局符号——swap 函数,而这个符号定义于另一个静态链接的目标文件 b.o 里面,那么a.o 的符号表(.symtab)里面的swap 符号类型只是一个引用,所以a.o 中的值暂时为0(即空地址)。另外细心的朋友还留意到上面的介绍中最终链接的输出可执行文件 ab 的.text 属性为 R E,即只读且可执行,那么运行时执行这些.text中包含的指令时对应的符号地址是需要确定下来,同时需要修改指令中对应符号的地址为对应的值。所以它只能在链接阶段确认下来,也就是静态链接阶段,这个过程就是我们所说的符号地址重定位。
那么重定位依赖哪些信息呢?它的工作原理是什么样的呢?我们带着这个问题继续往下看
-
重定位表在目标文件中的存在形式
重定位表在目标中是实际存在的,在目标文件生成的时候,它也随之生成。由于它并不是独立存在的,它是对指定section中的符号的重定位描述,所以它的命名也是对应的,例如对.text section的重定位表的命名为.rela.text(每个平台命名会有差异)。
我们继续以a.c 的例子详细了解这个过程。
例如 a.c 的代码如下:
|
1 2 3 4 5 6 7 |
extern int shared; extern void swap(int* a, int* b); int main() { int a = 100; swap(&a, &shared); } |
a.o 中 main函数引用了外部符号 swap,即a.o 的.text section中的引用了全局符号 swap。那么a.o也会对应一个.rela.text 重定位表。我们使用命名: readelf 来回顾一下a.o的 section内容:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
B-VL4BMD6M-2245 jni % readelf -S a.o There are 10 section headers, starting at offset 0x288: Section Headers: [Nr] Name Type Address Offset Size EntSize Flags Link Info Align [ 0] NULL 0000000000000000 00000000 0000000000000000 0000000000000000 0 0 0 [ 1] .strtab STRTAB 0000000000000000 00000212 0000000000000076 0000000000000000 0 0 1 [ 2] .text PROGBITS 0000000000000000 00000040 0000000000000034 0000000000000000 AX 0 0 4 [ 3] .rela.text RELA 0000000000000000 000001b0 0000000000000048 0000000000000018 9 2 8 [ 4] .comment PROGBITS 0000000000000000 00000074 0000000000000030 0000000000000001 MS 0 0 1 [ 5] .note.GNU-stack PROGBITS 0000000000000000 000000a4 0000000000000000 0000000000000000 0 0 1 [ 6] .eh_frame PROGBITS 0000000000000000 000000a8 0000000000000030 0000000000000000 A 0 0 8 [ 7] .rela.eh_frame RELA 0000000000000000 000001f8 0000000000000018 0000000000000018 9 6 8 [ 8] .llvm_addrsig LOOS+0xfff4c03 0000000000000000 00000210 0000000000000002 0000000000000000 E 9 0 1 [ 9] .symtab SYMTAB 0000000000000000 000000d8 00000000000000d8 0000000000000018 1 6 8 Key to Flags: W (write), A (alloc), X (execute), M (merge), S (strings), I (info), L (link order), O (extra OS processing required), G (group), T (TLS), C (compressed), x (unknown), o (OS specific), E (exclude), D (mbind), p (processor specific)w |
我们看到 .text 的重定位表 .rela.text,且它的类型为 RELA。.rela.text 包含什么内容呢,
我们使用 readelf -r 来查看:
|
1 2 3 4 5 6 7 8 9 10 11 |
B-VL4BMD6M-2245 jni % readelf -r a.o Relocation section '.rela.text' at offset 0x1b0 contains 3 entries: Offset Info Type Sym. Value Sym. Name + Addend 000000000018 000700000113 R_AARCH64_ADR_PRE 0000000000000000 shared + 0 00000000001c 000700000115 R_AARCH64_ADD_ABS 0000000000000000 shared + 0 000000000020 00080000011b R_AARCH64_CALL26 0000000000000000 swap + 0 Relocation section '.rela.eh_frame' at offset 0x1f8 contains 1 entry: Offset Info Type Sym. Value Sym. Name + Addend 00000000001c 000500000105 R_AARCH64_PREL32 0000000000000000 .text + 0 |
完成重定位工作重定位表需要具备这些重要信息:
- 符号在section中的位置(找到需要重定位的符号)
- 这个符号的重定位方式(如何修改符号地址,例如指定操作的地址是相对的还是绝对的)
- 这个符号在符号表中的位置(用于查询符号地址)
我们看下上面的重定位表的列名:
Offset:重定位入口的偏移,对于可重定位文件来说,这个值是该重定位入口所需要修正的位置的第一个字节相对于section起始的偏移。对于可执行文件或共享对象文件来说,这个值是该重定位入口所要修正的位置的第一个字节的虚拟地址。
Info:重定位入口的类型和符号。这个成员的低8位表示重定位入口的类型,高24位表示重定位入口的符号在符号表的下标。
Type:重定位类型,这里是arm 64处理器定义的一些重定位类型。这些类型描述了指令的修正方式。详细参考这两个链接:链接1、链接2
- 重定位的工作原理:
有了上面介绍的3个信息,链接器就能很好的将 .text section里面需要重定位的内容通过 .rela.text 这张重定位表来完成重定位了。由于这里比较偏细节,就不做详细展开了,感兴趣的同学可以翻阅《程序员的自我修养》第109页继续学习。
3.4.1.5、装载到内存
前面介绍过 “section” 和 “segment” 的区别,我们知道从链接的角度看,ELF文件是按“section”存储的,从装载角度看,ELF文件又可以按照“segment”划分。也就是装载时关注的是segment。
从本节的大图中我们看到可执行文件的多个segment分别被映射到进程虚拟内存空间的多个VMA(Virtual Memory Area, 虚拟内存区域)。我们可以通过查看运行时的进程虚拟空间分布进一步分析~
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
130|root@x86_64:/sdcard/test # ./ab & [1] 13862 root@x86_64:/sdcard/test # cat /proc/13862/maps 7f67dcf40000-7f67dd140000 rw-p 00000000 00:00 0 7f67dd15d000-7f67dd1ae000 r-xp 00000000 08:06 1604 /system/lib64/libm.so 7f67dd1ae000-7f67dd1af000 r--p 00050000 08:06 1604 /system/lib64/libm.so 7f67dd1af000-7f67dd1b0000 rw-p 00051000 08:06 1604 /system/lib64/libm.so 7f67dd1b0000-7f67dd2a1000 r-xp 00000000 08:06 1536 /system/lib64/libc++.so 7f67dd2a1000-7f67dd2a9000 r--p 000f0000 08:06 1536 /system/lib64/libc++.so 7f67dd2a9000-7f67dd2aa000 rw-p 000f8000 08:06 1536 /system/lib64/libc++.so 7f67dd2aa000-7f67dd2ad000 rw-p 00000000 00:00 0 7f67dd2ad000-7f67dd2af000 r-xp 00000000 08:06 1619 /system/lib64/libnetd_client.so 7f67dd2af000-7f67dd2b0000 r--p 00001000 08:06 1619 /system/lib64/libnetd_client.so 7f67dd2b0000-7f67dd2b1000 rw-p 00002000 08:06 1619 /system/lib64/libnetd_client.so 7f67dd2b1000-7f67dd2b3000 rw-p 00000000 00:00 0 7f67dd2b3000-7f67dd2b5000 rw-p 00000000 00:00 0 7f67dd2b6000-7f67dd2d6000 r--s 00000000 00:0e 6483 /dev/__properties__ 7f67dd2d6000-7f67dd2d7000 rw-p 00000000 00:00 0 7f67dd2d7000-7f67dd3d2000 r-xp 00000000 08:06 1537 /system/lib64/libc.so 7f67dd3d2000-7f67dd3d9000 r--p 000fa000 08:06 1537 /system/lib64/libc.so 7f67dd3d9000-7f67dd3dc000 rw-p 00101000 08:06 1537 /system/lib64/libc.so 7f67dd3dc000-7f67dd3ed000 rw-p 00000000 00:00 0 7f67dd3ed000-7f67dd3ef000 r--p 00000000 00:00 0 7f67dd3ef000-7f67dd3f0000 rw-p 00000000 00:00 0 7f67dd3f0000-7f67dd3f1000 r--p 00000000 00:00 0 7f67dd3f1000-7f67dd411000 r--s 00000000 00:0e 6483 /dev/__properties__ 7f67dd411000-7f67dd412000 r--p 00000000 00:00 0 7f67dd412000-7f67dd413000 ---p 00000000 00:00 0 7f67dd413000-7f67dd417000 rw-p 00000000 00:00 0 7f67dd417000-7f67dd457000 r-xp 00000000 08:06 212 /system/bin/linker64 7f67dd457000-7f67dd458000 r--p 0003f000 08:06 212 /system/bin/linker64 7f67dd458000-7f67dd45a000 rw-p 00040000 08:06 212 /system/bin/linker64 7f67dd45a000-7f67dd45f000 rw-p 00000000 00:00 0 7f67dd45f000-7f67dd460000 r-xp 00000000 08:13 7832589 /storage/emulated/0/test/ab 7f67dd460000-7f67dd461000 r--p 00000000 08:13 7832589 /storage/emulated/0/test/ab 7f67dd461000-7f67dd462000 rw-p 00001000 08:13 7832589 /storage/emulated/0/test/ab 7ffcdb876000-7ffcdb897000 rw-p 00000000 00:00 0 [stack] 7ffcdb922000-7ffcdb924000 r--p 00000000 00:00 0 [vvar] 7ffcdb924000-7ffcdb926000 r-xp 00000000 00:00 0 [vdso] ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall] |
我们虚拟内存空间的映射来看,可执行文件ab 的3个segment在进程虚拟内存空间里面映射了3个VMA,分别大小为一页(0x1000,这里是4K)。
系统映射了可执行文件后,会初始化进程环境,并将系统调用的返回地址修改成可执行文件的入口点,对于静态链接来说它就是ELF文件头的Entry point address(我们可以通过 readelf -l xxx来查看)。对于静态链接的可执行程序系统调用执行完从内核态返回到用户态时就转到了这个入口函数地址开始执行,至此ELF可执行文件装载完成。
3.4.2、动态链接
在静态链接时,整个程序最终只有一个可执行文件,它是一个不可分割的整体。随着代码规模的日益增大,我们会抽取越来越多的库方便复用,而静态链接的设计会导致内存和磁盘空间的浪费、更新库的版本时需要程序重新链接发布、另外也无法制作插件等问题~
动态链接的产生是为了解决这些不足,包括:
- 静态链接带来的内存和磁盘空间浪费问题
- 依赖库版本更新无需重新链接
- 制作程序的插件,拓展程序功能
- 动态链接库可以做为程序与操作系统之间的适配层
在动态链接下,一个程序被分成了若干个文件,包括程序的主要部分和程序所依赖的共享对象,很多时候大家也把这些部分称为模块,即动态链接下的可执行文件和共享对象都可以看做是程序的一个模块。
我们也同样用一张大图来描述动态链接的场景下从源码到装载到内存过程中发生了什么~

动态链接这个图中多了一个我们自己写的lib.so动态共享库模块,同时也有一个外部库libc.so 动态共享库模块。这两个动态共享库可以在多个可执行程序间复用,且在内存中只分配一次内存(代码段内容只占有一份内存,数据段因为会修改所以不会复用)。看起来动态链接的这种多个模块的加载更符合我们当下的程序开发的应用场景。而静态链接也不是一无是处,很多场景是相对简单的,静态链接能完全满足,且是简单有效的。
动态链接的过程可以概括如下:
- 可执行程序program1 和 program2 被装载到进程虚拟内存空间,系统将入口指向了该动态链接器执行(可执行程序的 .interp section保存了动态链接库的路径)
- 动态链接器从 可执行程序的 .dynamic section 读取当前可执行程序依赖的外部动态库,并装载到进程虚拟空间
- 动态链接器将各个动态库的动态符号表(.dynsym) 收集到全局符号表。
- 动态链接器完成符号的重定位
- 动态链接器处理完成后交给用户进程空间的入口函数地址继续执行
接下来详细了解一下这个过程~ 我们同样按图中准备3个源代码文件:lib.c, program1.c, program2.c
lib.c:
|
1 2 3 4 5 6 7 |
#include "lib.h" int main() { foobar(1); return 0; } |
lib.h
|
1 2 3 4 5 |
#ifndef TESTEMPTY_LIB_H #define TESTEMPTY_LIB_H void foobar(int i); #endif //TESTEMPTY_LIB_H |
program1.c
|
1 2 3 4 5 6 7 |
#include "lib.h" int main() { foobar(1); return 0; } |
program2.c
|
1 2 3 4 5 6 7 |
#include "lib.h" int main() { foobar(2); return 0; } |
program1.c 和 program2.c 都依赖 lib.c,它们会编译为可执行程序,而lib.c会编译成动态共享库。lib.c里面定义了foobar全局符号,而program1 和 program2 引用了这个全局符号。
我们先通过下面的命令得到我们想要的文件:
|
1 2 3 |
B-VL4BMD6M-2245 jni % x86_64-linux-android28-clang -fPIC -shared -o lib.so lib.c B-VL4BMD6M-2245 jni % x86_64-linux-android28-clang -o program1 program1.c ./lib.so B-VL4BMD6M-2245 jni % x86_64-linux-android28-clang -o program2 program2.c ./lib.so |
3.4.2.1、认识动态共享库的section:.interp & .dynamic & .dynsym
与静态链接不同的是由于program1和program2依赖的lib.so 是动态共享库,所以program1和program2都会有一个动态链接表(.dynamic)和 动态符号表(.dynsym),它们两之间的区别可以回顾上面这里的介绍。动态链接时无需再关心符号表的内容,而只需要关心这两个表:动态链接表(.dynamic)和 动态符号表(.dynsym)。另外为了找到动态链接库我们还需要.interp section。
我们可以通过readelf 查看文件中这3个部分的内容:
.interp
|
1 2 |
B-VL4BMD6M-2245 jni % readelf -l program1 | grep interpreter [Requesting program interpreter: /system/bin/linker64] |
我们看到可执行程序依赖的动态链接器的路径是/system/bin/linker64
.dynamic
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
B-VL4BMD6M-2245 jni % readelf -d program1 Dynamic section at offset 0xd98 contains 29 entries: Tag Type Name/Value 0x0000000000000003 (PLTGOT) 0x1fc8 0x0000000000000002 (PLTRELSZ) 96 (bytes) 0x0000000000000017 (JMPREL) 0x4a8 0x0000000000000014 (PLTREL) RELA 0x0000000000000007 (RELA) 0x478 0x0000000000000008 (RELASZ) 48 (bytes) 0x0000000000000009 (RELAENT) 24 (bytes) 0x000000006ffffff9 (RELACOUNT) 2 0x0000000000000015 (DEBUG) 0x0 0x0000000000000006 (SYMTAB) 0x2e8 0x000000000000000b (SYMENT) 24 (bytes) 0x0000000000000005 (STRTAB) 0x3a8 0x000000000000000a (STRSZ) 106 (bytes) 0x000000006ffffef5 (GNU_HASH) 0x418 0x0000000000000001 (NEEDED) Shared library: [./lib.so] 0x0000000000000001 (NEEDED) Shared library: [libdl.so] 0x0000000000000001 (NEEDED) Shared library: [libc.so] 0x0000000000000020 (PREINIT_ARRAY) 0x1d68 0x0000000000000021 (PREINIT_ARRAYSZ) 16 (bytes) 0x0000000000000019 (INIT_ARRAY) 0x1d78 0x000000000000001b (INIT_ARRAYSZ) 16 (bytes) 0x000000000000001a (FINI_ARRAY) 0x1d88 0x000000000000001c (FINI_ARRAYSZ) 16 (bytes) 0x000000000000001e (FLAGS) BIND_NOW 0x000000006ffffffb (FLAGS_1) Flags: NOW 0x000000006ffffff0 (VERSYM) 0x448 0x000000006ffffffe (VERNEED) 0x458 0x000000006fffffff (VERNEEDNUM) 1 0x0000000000000000 (NULL) 0x0 |
其中我们关注 Type 为 NEEDED 的3个shared library:./lib.so, libdl.so,libc.so。其中lib.so是我们编译lib.c生成的动态共享库,其它两个是系统库,libdl.so是提供动态链接相关的支持(详细见:链接),libc.so是C的标准库(详细见:链接)。.dynamic描述了整个program可执行程序的动态库依赖关系树(每个动态库也有自己的.dynamic section,也描述了它自己依赖了哪些其它的动态库)。动态链接器就是按照这棵树把所有依赖的动态共享库都映射到进程的虚拟内存空间的。
我们再来看下动态符号表~
.dynsym
|
1 2 3 4 5 6 7 8 9 10 11 12 |
B-VL4BMD6M-2245 jni % readelf -sD program1 Symbol table for image contains 8 entries: Num: Value Size Type Bind Vis Ndx Name 0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND 1: 0000000000000000 0 FUNC GLOBAL DEFAULT UND __cxa_atexit@LIBC (2) 2: 0000000000000000 0 FUNC GLOBAL DEFAULT UND __regis[...]@LIBC (2) 3: 0000000000000000 0 FUNC GLOBAL DEFAULT UND __libc_init@LIBC (2) 4: 0000000000000000 0 FUNC GLOBAL DEFAULT UND foobar 5: 0000000000002000 0 NOTYPE GLOBAL DEFAULT ABS _edata 6: 0000000000002008 0 NOTYPE GLOBAL DEFAULT ABS _end 7: 0000000000002000 0 NOTYPE GLOBAL DEFAULT ABS __bss_start |
我们重点看3个列:Type,Ndx,Name
Type为 GLOBAL 代表这是一个全局符号;
Ndx 为UND (undefined) 代表该符号未在当前文件定义,它是一个对外部符号的引用;
Name 为符号名;我们一眼就看出了4个UND的全局符号。先抛开3个系统的符号不看,我们看到了我们定义在lib.so 动态共享库的全局符号引用 foobar。
从上面动态符号表这里的描述中我们知道了:动态符号表只保存了模块中符号导出、导入信息。这个是专门为了动态链接使用的表,用于表示动态链接这些模块之间的符号导入导出关系。
所以我们知道 .dynamic 和 dynsym 两张表帮助动态链接器把可执行程序和多个动态共享库很好的结合起来了。
上面介绍的这些动态链接相对静态链接额外多出的几个section,目的是实现从静态链接的一个完整文件到动态链接拆分为多个模块的架构。
那么既然架构满足了拆分多个模块,实现了文件内容可复用,而实际中除了内容可复用,我们还希望共享库占用的内存也可复用,而不是每个进程复制一份共享库的内容到自己的进程虚拟空间。这样对于内存的消耗也是相当大的。如何解决这个问题,我们需要结合链接的知识继续分析,了解共享库中哪些内容能做到内存级别可复用,哪些是无法做到的。
这个引出了下一个话题——地址无关代码
3.4.2.2、地址无关代码
实现内存可复用的问题点在哪?
从静态链接中我们知道代码段(.text section)里面会引用符号的地址,所以会有对应的重定位表(.rela.text)、那么每个进程引用符号的位置肯定参差不齐,一旦触发重定位了,那么代码段就无法在其它进程实现内存复用了,只能重新拷贝.text 到新的进程,完成新的重定位操作才能使用。
地址无关的思路
那么怎么解决这个问题呢?套用IT某位名人的一句话:“所有问题都可以通过增加一层来解决”。
这里也不例外,要实现代码段可复用,我们将代码中可变的部分剥离出去。例如代码里面引用的符号能否做到地址无关?ELF格式引入了—— GOT 和 PLT 。它类似于我们常说的代理模式,代理模式就是在可变和不变的中间增加一层,实现解耦。
那么为什么要引入两个呢?我总结是这样的,PLT是对GOT的进一步优化,这是因为全局符号一般分为2两种:变量和函数,出于设计考虑,一般共享库对外的公开的符号主要是函数,而尽量不会使用变量,也就是一般全局函数符号相对于全局数据符号多很多。同时一个标准库中公开的所有函数不需要都进行重定位操作,那样对于动态链接库这种运行时处理动态共享库会效率非常低,只有用到的时候才需要,而一个程序中用到的标准库中的函数一般远远小于库本身公开的数量。基于这个背景,动态共享库分为了两个表GOT和PLT。GOT 用于保存全局变量引用的地址,而PLT 用来保存外部函数的引用地址。另外PLT 使用延迟加载法,即只有在第一次被过程调用时,才解析它的地址,因此延迟加载法可以提高程序启动的速度。
PLT & GOT

GOT是一张中间代理这些外部符号的一张中间表,它存在于数据段,是可在运行时修改的,同时它相对于.text的偏移已经固定,就如同.data相对于.text是固定的一样的道理。那么此时.text已经做到了地址无关,也就说明.text做到了代码间“真正”的可复用。
我们看下它具体是怎么做的,首先GOT也拆分成了两部分,针对PLT单独有个.GOT.PLT,里面保存了导入符号需要依赖的相关信息:动态链接表(.dynamic)的位置、本模块ID、动态链接器_dl_runtime_resolve函数的地址。其它的都是每个外部符号的地址填入。而.GOT里面每项直接就是外部全局符号变量的地址填入了。
编译地址无关的动态共享库
编译时添加PIC flag,示例如下:
|
1 |
x86_64-linux-android28-clang -fPIC -shared -o lib.so lib.c |
在动态链接器完成了动态共享库的装载和符号重定位后,接下来动态链接器返回到可执行程序的入口地址继续执行,到此动态链接场景下程序就运行起来了~
4、总结
至此我们对编译、链接、装载有了整体的认识了。并没有想象中的那样复杂,之所以那么神秘,一个是这个知识点面向是的一些二进制文件,不直观。另一个是一些差异性,在不同的硬件平台有不同的ABI定义。但是不管怎么不同他们的原理都是一致,都会包含我上面重点高亮的这些词汇,只要我们理解了这些词汇,不同平台的差异也能触类旁通,比较容易去理解了。另外系统也提供了很强大的工具帮助我们查看这些二进制文件,例如文章提到的readelf 和 objdump等。善于使用这些工具也能让这些底层的过程清晰的浮现在我们的眼前。
最后还是要感谢《程序员的自我修养》的作者带领我们领略了这么深奥的知识,如果想要获取更细的知识,也是建议回到书中寻找答案。希望我的这篇文章是一篇敲门砖,帮助读者打开了编译、链接、装载的大门!











