
 花花鞋
花花鞋
1、为什么要抛弃 Javac/dx,开发 Jack 和 Jill
推测主要有三个目的
- 提高编译速度
- 应对 Oracle 的法律诉讼
- 将编译器掌控权拿在自己手中,不再受制于 Oracle,可以做一些 Android only 的优化
下面比较一下旧的 javac/dx/ProGuard/jarjar toolchain 和新的 Jack 编译器的工作流程
2、旧的编译流程
简单的说,将 Java 代码和依赖库编译为 dex 有两个大的阶段
javac (.java –> .class) –> dx (.class –> .dex)
下面是用流程图表示的旧编译过程:
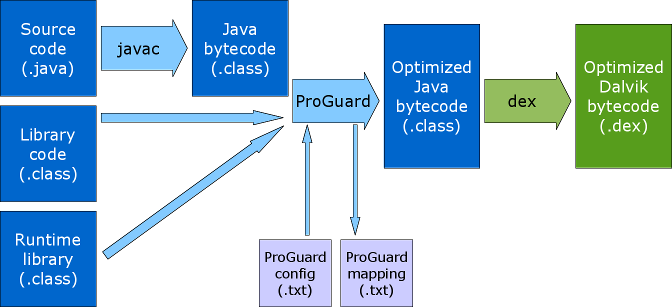
- javac 将 java 代码编译为 java bytecode, 以
.class的形式存在; 以 jar 和 aar 形式存在的依赖库,代码在里面以一堆.class 的形式存在 - Proguard 工具读取 Proguard 配置,对
.class做 shrinking, obfuscation,输出 Proguard mapping - dx 将多个
.class转化为单一的 classes.dex ; 如果 dex 方法数超过 65k, 就生成 classes.dex, classes1.dex…classesN.dex
3、新的编译流程
新的编译过程只有一个阶段了,它完全抛弃了 javac, ProGuard, jarjar 等工具,一个工具搞定一切
Jack (.java –> .jack –> .dex)
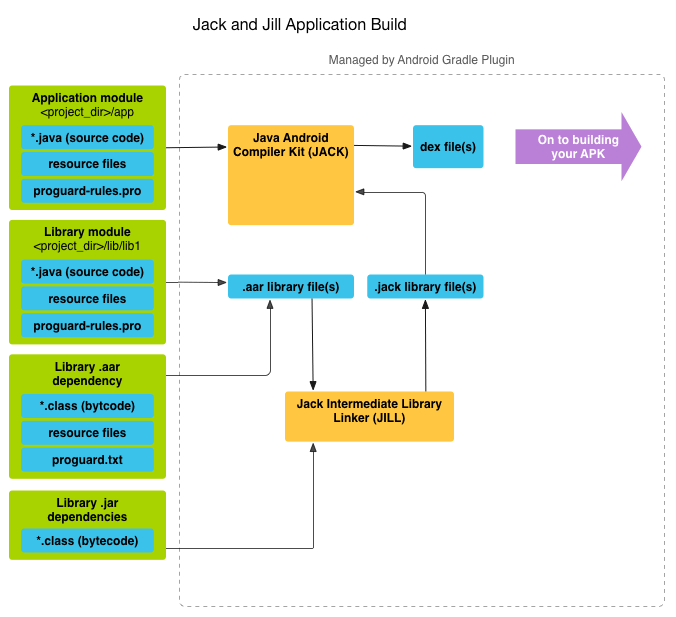
- 各种依赖库仍然以 jar/aar 的形式存在
- 辅助工具 Jill 将根据依赖库中的
.class生成 Jayce 格式的 IL,并调用 Jack 做 pre-dex 并生成.jack,此过程只在编译 app 时发生一次 - Jack 将 java 源代码也编译为
.jack,然后将多个.jack转化为单一的.dex; 如果 dex 方法数超过 65k, 就生成 classes.dex, classes1.dex…classesN.dex
Jill的工作:Jill工具具体的工作就是将jar/aar中的.class文件转化成.jayce格式的文件,并且再使用Jack做preDex操作。至于preDex的作用,其实就是一个预编译的作用,起到缓存的作用
Jack的工作:Jack使用了Jill工具将依赖库中的.class文件转换成了.jack文件,然后再使用Jack工具将这些文件和Android过程的源代码一起编译为.dex文件,当然.dex文件的数量取决于是否开启multiDex。
3.1、.Jack中间文件
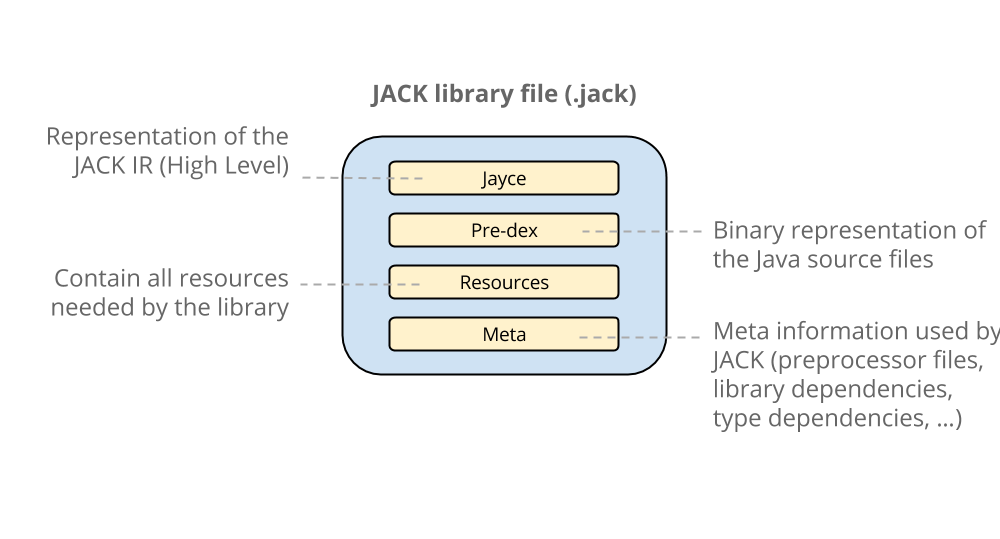
里面包含了 Jayce 格式的 IL ,pre-dex,原始 aar 中的资源文件,以及 Jack 会用到的一些 meta 信息
下图简单比较了 java 代码转化的 .class, Jayce IL 和 dex 的内容异同:
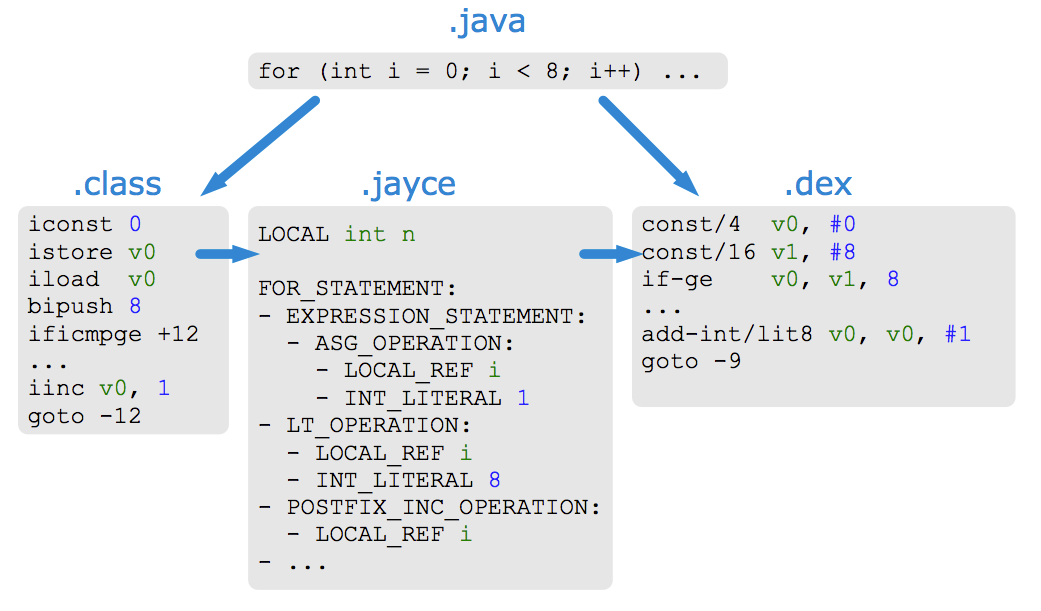
简单比较下三种 IL 的区别:
- Sun/Oracle Hotspot VM 是基于栈式的,所以
.class文件的内容就是不断地压操作数到栈顶,从栈顶读取操作数,比较或做运算,将结果再压回栈顶 - Dalvik VM 是基于寄存器的,所以
.dex的内容就是不断地 move 操作数到寄存器,比较或做运算,将结果写回寄存器或内存地址 - Jayce 则是 Jack&Jill 专有的 IL, 目前没有查阅到更多的官方资料。只能参阅 Jill 源代码中 com.android.jill.backend.jayce 包的代码了,比如其中的 Token 类就定义了 Jayce 的 Token 定义。
个人推测 Jayce 存在的意义是:
- 为了在整合多个 jack 文件,生成单一的 dex 时,方便 Jack 做一些全局性的后端编译优化。
- 从 Android 生态圈中完全去除 Oracle 的 Java Bytecode 格式











